リアルタイム処理を最適化|ストリーミングETL性能向上の実践ガイド
リアルタイムデータ活用がビジネスの競争優位性を左右する現代において、ストリーミングETLの性能は重要な戦略資産です。しかし、「レイテンシが高くリアルタイム性が不十分」「スループットが伸びずボトルネックが発生」「クラウドコストが想定以上に高くなる」といった課題を抱える企業様も多いのではないでしょうか。
こちらでは、ストリーミングETLの最適化戦略から実装、運用まで、システム開発会社の視点で実践的な手法を詳しく解説します。Apache Kafka、Amazon Kinesis、Apache Sparkなどの最新技術を活用し、レイテンシ削減、スループット向上、コスト最適化を同時に実現する包括的なアプローチをご紹介します。
ストリーミングETL最適化の必要性とパフォーマンス改善効果
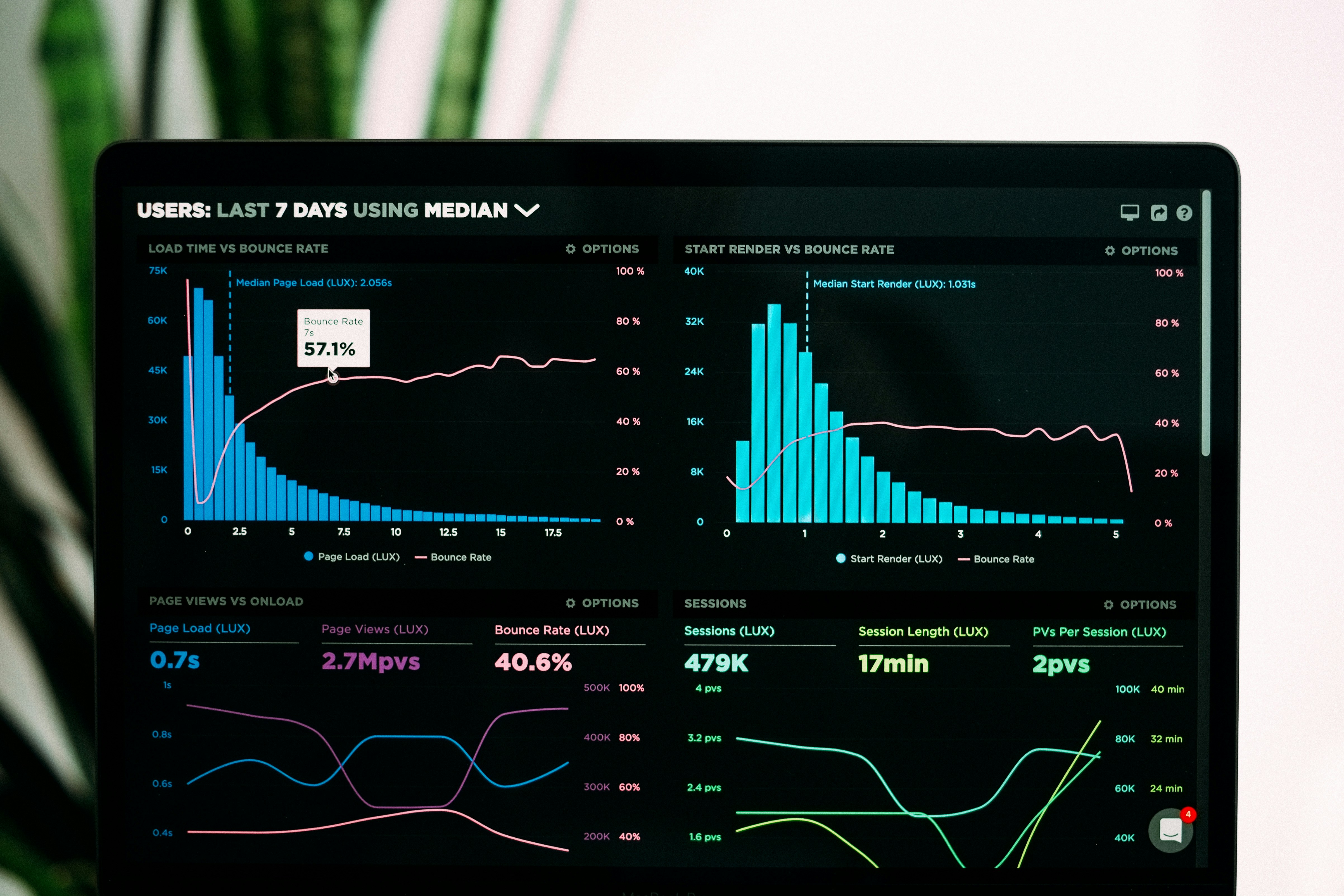
ストリーミングETLの最適化は、リアルタイムデータ処理の性能と効率性を飛躍的に向上させる重要な戦略です。伝統的なバッチ処理の限界を超えて、低レイテンシで高スループットのリアルタイムデータ基盤を構築するために、最適化戦略の必要性と改善効果を整理します。
レイテンシ高騰化とリアルタイム性の課題
ストリーミングETLでは、データの収集から分析結果の出力までのレイテンシがビジネス価値を左右します。適切な最適化が行われないと、ネットワークやシリアライゼーションのオーバーヘッドにより、リアルタイム性が大幅に殻損し、ビジネス機会の逸失につながります。
スループットボトルネックとリソース非効率
データ量と速度が増加すると、既存の処理アーキテクチャではスループットボトルネックが発生します。適切なパーティショニング、パラレル処理、リソーススケーリングが実装されないと、システムの可用性やパフォーマンスが大幅に低下し、ビジネス継続性に影響を与えます。
コスト効率悪化とリソースの無駄使用
ストリーミング処理では、不適切なリソース配置や非効率なアーキテクチャがコスト増大の大きな要因となります。不必要なコンピュートリソース、非効率なデータシリアライゼーション、不適切なキャッシュ戦略により、運用コストが想定を超えるリスクがあります。
監視と障害対応の課題
リアルタイムシステムでは、僅かな障害や性能低下でもビジネスへの影響が極めて大きくなります。適切な監視ツール、アラートシステム、自動復旧機構が実装されないと、問題の発見が遅れ、サービスへの影響が長期化するリスクがあります。
データパイプライン自動化の技術スタックと選定基準

ストリーミングETLの最適化を成功させるためには、適切な技術スタックとアーキテクチャの選定が重要です。データの特性、レイテンシ要件、スケーラビリティ要求、コスト制約を総合的に考慮し、最適なツールとプラットフォームを選択する必要があります。主要な技術オプションと選定基準を解説します。
Apache Kafkaによる高スループットメッセージング
Apache Airflowは、複雑なデータワークフローをDAG(有向非巡回グラフ)として定義し、スケジューリングと実行を自動化します。Pythonベースの柔軟な開発、豊富なオペレーター、強力な監視機能により、エンタープライズ級のパイプライン自動化を実現します。
dbtによるデータ変換の自動化
dbt(data build tool)は、SQLベースのデータ変換をバージョン管理可能な形で自動化します。データの品質テスト、ドキュメント自動生成、依存関係管理などの機能により、信頼性の高いデータ変換パイプラインを構築できます。
AWS Glueによるサーバーレスデータ統合
AWS Glueは、サーバーレスのデータ統合サービスとして、ETL処理の自動化を実現します。データカタログ、ジョブスケジューリング、自動スケーリングなどの機能により、運用負荷を最小限に抑えながら、大規模なデータ処理を実行できます。
リアルタイム処理の自動化
Apache Kafka、Amazon Kinesis、Apache Flinkなどのストリーミング技術を活用し、リアルタイムデータパイプラインを自動化します。イベントドリブンアーキテクチャにより、データの到着と同時に処理を開始し、低レイテンシーでのデータ活用を実現します。
ストリーミングETL最適化の実装パターンと性能向上手法
ストリーミングETLの最適化には、業界で実証された実装パターンと性能向上手法が存在します。これらの手法を適用することで、低レイテンシかつ高スループットの堅牢なストリーミングシステムを構築できます。実践的な最適化パターンと重要な考慮事項を解説します。
エラーハンドリングとリトライ戦略
自動化パイプラインでは、適切なエラーハンドリングが不可欠です。一時的な障害に対する自動リトライ、エラー通知、フォールバック処理などを実装します。指数バックオフ、サーキットブレーカーパターンなどの高度な手法により、システムの安定性を確保します。
データ品質チェックの自動化
パイプラインの各段階でデータ品質をチェックする自動化機構を実装します。スキーマ検証、データ型チェック、異常値検出、完全性確認などを自動実行し、問題を早期に検出します。Great ExpectationsやDeequ などのツールを活用し、包括的な品質管理を実現します。
モニタリングとアラート設計
パイプラインの実行状況、処理時間、エラー率などのメトリクスを自動収集し、ダッシュボードで可視化します。閾値を超えた場合の自動アラート、SlackやPagerDutyとの連携により、問題の早期発見と迅速な対応を可能にします。
テストとCI/CDの統合
パイプラインコードの単体テスト、統合テスト、エンドツーエンドテストを自動化します。GitHubActionsやJenkinsなどのCI/CDツールと統合し、コード変更時の自動テスト実行、ステージング環境での検証、本番環境への自動デプロイを実現します。
コスト最適化と自動スケーリング
クラウド環境でのパイプライン実行コストを最適化する自動化機構を実装します。処理量に応じた自動スケーリング、スポットインスタンスの活用、処理完了後の自動リソース解放などにより、パフォーマンスとコストのバランスを実現します。
データパイプライン自動化の導入アプローチと成功事例
データパイプライン自動化の導入は、段階的なアプローチにより成功確率を高めることができます。小規模な実証実験から始め、徐々に適用範囲を拡大することで、リスクを最小化しながら効果を最大化できます。実践的な導入アプローチと成功のポイントを解説します。
現状分析と優先順位付け
既存のデータパイプラインを棚卸しし、手動作業の頻度、エラー発生率、業務影響度を分析します。自動化による効果が高く、技術的難易度が低いパイプラインから優先的に自動化を進めることで、早期に成果を実感できます。
パイロットプロジェクトによる検証
選定したパイプラインでパイロットプロジェクトを実施し、技術的な実現可能性と効果を検証します。小規模な範囲で自動化の恩恵を実証し、組織内の理解と支持を獲得します。この段階で得られた知見を、本格展開に活用します。
段階的な展開と継続的改善
パイロットプロジェクトの成功を基に、段階的に自動化を展開します。各段階でフィードバックを収集し、プロセスやツールを改善します。自動化の効果測定を継続的に実施し、ROIを可視化することで、さらなる投資の正当性を示します。
組織文化とスキル育成
自動化の成功には、技術だけでなく組織文化の変革も必要です。データエンジニアリングチームのスキル育成、自動化マインドセットの醸成、失敗を許容する文化の構築などにより、持続可能な自動化体制を確立します。
ストリーミングETL最適化で実現するビジネス価値
ストリーミングETL最適化は、単なる技術的な改善にとどまらず、企業のビジネス価値を大幅に向上させる戦略的な投資です。リアルタイムデータの活用により、迅速な意思決定、顧客体験の向上、新たなビジネス機会の創出が可能になります。
TechThanksでは、お客様のデータ活用戦略と既存システムを詳しく分析し、最適なストリーミングETL最適化ソリューションをご提案しています。Apache Kafka、Amazon Kinesis、Apache Sparkなどの最新技術を活用し、低レイテンシで高スループットのリアルタイムデータ基盤の構築を支援いたします。
ストリーミングETL最適化についてご相談がございましたら、まずは現状の課題と目指すべき姿をお聞かせください。実証済みの手法と豊富な経験を基に、最適な最適化戦略をご提案いたします。